
O framework Dozer é um parser de um POJO para outro POJO, o que significa dizer que ele copia automaticamente, de forma recursiva, dados de um objeto para outro.
O Dozer supporta mapear propriedades simples, tipos complexos, mapeamento bidirecional, mapeamento implicito-explicito, suporta também o mapeamento de coleções de atributos.
O Dozer suporta não somente o mapeamento entre nomes de atributos mas também faz conversões entre tipos. Para cenários mais complexos o Dozer permite realizar conversões customizadas através de arquivos XML.
O mapper é indicado sempre que você precisa copiar as informações de um POJO para outro. A maioria dos atributos podem ser mapeados automaticamente pelo Dozer através de reflexão, mas, como já foi comentado, qualquer mapeamento customizado pode ser feito através de arquivos XML. O mapeamento é bi-direcional somente o relacionamento entre as classes precisa ser definido. Se qualquer nome de alguma propriedade em ambos os objetos forem iguais você não precisará fazer nenhum mapeamento adicional para mapear essas propriedades.
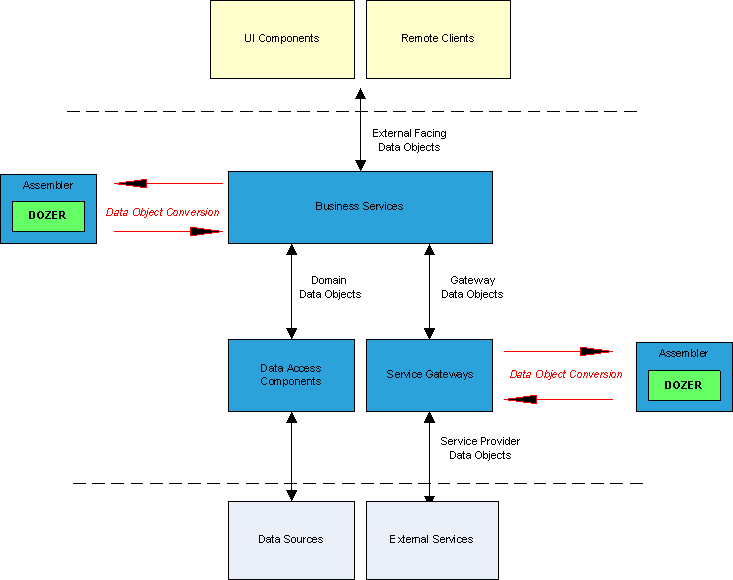
A figura abaixo representa um exemplo em que é recomendável utilizar o Dozer em uma arquitetura. Note que ele é tipicamente usado nas entradas e saídas da aplicação. O Dozer garante que seus objetos de domínio interno não sejam vistos pelas camadas de apresentação ou por consumidores externos. Ele também pode ajudar a mapear seus objetos de domínio para chamadas externas de API’s e vice versa.
Em outras palavras, ao invés de você expor suas entidades JPA, por exemplo, o que indiretamente tornaria públicas informações de sua base de dados, você cria um POJO similar às suas entidades JPA, só que sem as anotações, e expõe esse POJO para os clientes de sua aplicação. Entre o POJO exposto e o a entidade JPA você poderia utilizar um framework como o Dozer e parsear dados de suas entidades JPA para o POJO exposto e vice e versa, encapsulando informações importantes de sua aplicação.
O Parser – “DozerParser”
No nosso exemplo temos um Parser genérico fazendo conversão de dois POJOS simples. Inicialmente criamos uma instância do Mapper, posteriormente temos dois métodos responsáveis por parsear um objeto e uma lista de objetos respectivamente.
Note que eles recebem objetos genéricos, o que significa que você pode usar da forma como está em um projeto seu que já vai funcionar. Logo abaixo temos um terceiro método que é quem efetivamente faz a invocação ao Dozer e este por sua vez realiza o parse.
package br.com.semeru.dozer.converter;
import java.util.ArrayList;
import java.util.List;
import org.dozer.DozerBeanMapper;
import org.dozer.Mapper;
public class DozerParser {
private static final Mapper dozerMapper = new DozerBeanMapper();
public static <o, d=""> D parseObjectInputToObjectOutput(O originalObject, Class<d> destinationObject) {
return parser(destinationObject, originalObject);
}
public static <o, d=""> List<d> parserListObjectInputToObjectOutput(List<o> originalObjects, Class<d> destinationObject) {
List<d> destinationObjects = new ArrayList<d>();
for (Object originalObject : originalObjects) {
destinationObjects.add(parser(destinationObject, originalObject));
}
return destinationObjects;
}
private static <d> D parser(Class<d> destinationObject, Object originalObject) {
return dozerMapper.map(originalObject, destinationObject);
}
}
O objeto de origem – “InputObject”
Aqui temos um objeto de entrada, que é um POJO simples.
package br.com.semeru.dozer.objects;
import java.io.Serializable;
public class InputObject implements Serializable {
private static final long serialVersionUID = 1L;
private String name;
private Integer age;
// Getters, setters, equals e hashCode omitidos
}
O objeto de destino – “OutputObject”
Aqui temos o segundo POJO para onde os dados do objeto de entrada serão copiados. Note que a extrutura dos POJO’s devem ser iguais. Caso contrário você deveria personalizar o parser de acordo com a sua necessidade usando arquivos XML.
package br.com.semeru.dozer.objects;
import java.io.Serializable;
public class OutputObject implements Serializable {
private static final long serialVersionUID = 1L;
private String name;
private Integer age;
// Getters, setters, equals e hashCode omitidos
}
A classe de Mock – “MockInputObject”
Aqui temos uma classe de Mock que cria uma instância do POJO de entrada e popula-o com informações simulando um acesso à uma base de dados por exemplo.
package br.com.semeru.dozer.mocks;
import br.com.semeru.dozer.objects.InputObject;
import java.util.ArrayList;
import java.util.List;
public class MockInputObject {
private InputObject inputObject = new InputObject();
public InputObject mockInput() {
inputObject.setName("Name Test");
inputObject.setAge(21);
return inputObject;
}
public List<inputobject> mockInputList() {
List<inputobject> inputObjects = new ArrayList<inputobject>();
for (int i = 0; i < 3; i++) {
inputObjects.add(mockInput(i));
}
return inputObjects;
}
private InputObject mockInput(Integer number) {
inputObject.setName("Name Test " + number);
inputObject.setAge(20 + number);
return inputObject;
}
}
Os testes – “DozerParserTest”
Por fim temos os testes unitários que são responsáveis por verificar o comportamento do parser pasando as instancias mockadas pela classe acima pelo nosso parser e realizando asserções nos resultados.
package br.com.semeru.dozer.converter;
import br.com.semeru.dozer.mocks.MockInputObject;
import java.util.List;
import junit.framework.Assert;
import org.junit.Before;
import org.junit.Test;
import br.com.semeru.dozer.objects.OutputObject;
public class DozerParserTest {
MockInputObject inputObject;
@Before
public void setUp() {
inputObject = new MockInputObject();
}
@Test
public void parseObjectInputToreObjectOutputTest() {
OutputObject output = DozerParser.parseObjectInputToObjectOutput(inputObject.mockInput(), OutputObject.class);
Assert.assertEquals("Name Test", output.getName());
Assert.assertTrue(output.getAge() == 21);
}
@Test
public void parserListObjectInputToObjectOutputTest() {
List<outputobject> output = DozerParser.parserListObjectInputToObjectOutput(inputObject.mockInputList(), OutputObject.class);
Assert.assertEquals("Name Test 2", output.get(0).getName());
Assert.assertTrue(output.get(0).getAge() == 22);
}
}
Enfim o Dozer é uma ótima opção de parser de um POJO para outro sendo também bastante simples de se usar. Como alternativa ao Dozer temos o Orika que faz as mesmas tarefas que o Dozer. No meu Github você pode ver um exemplo básico de utilização do Dozer e do Orika. Bom proveito e faça bons estudos.
Treinamentos relacionados com este post






